
Elastic ON tour 2017
Paris 30/01/2018
Introduction
Hacknowledge engineers have attended ElasticOn in January 2018. Here is our feedback/summary of this event.
Roadmap:
- Keynotes
- Deep Dive Elasticsearch
- Ingesting data into Elasticsearch
- Elastic at the core of “Data Lake de Renault”
- Deep Dive of Kibana
- Deep Dive machine learning
- Elastic Suite Integration at Amadeus
- Multiple clusters management with ElastiCloud Enterprise
Keynotes
Some remarks by Shay Bannon, CEO of Elastic on the history of the project, the current state of the platform, merging announcement with Swiftype and future developments.
Deep Dive Elasticsearch
Some history on the last releases of Elasticsearch, major improvements on simplicity and data management.
Starting from ES (Elasticsearch) 5.0, some efforts have been done on the security side, introducing encrypted APIs while migrating from a keyword-search approach to a better indexing of numeric fields. The whole project has been re-designed keeping in mind that “simple things must be simple” as stated by Shay Bannon in the keynotes.
Moving to ES 5.6, other many improvements have been introduced such as:
-
keyword normalization
-
unified highlighter
-
field collapsing
-
multy word synonyms and proximity
-
stoppable searches
-
parallel scroll and re-index
-
improvements on structured data
-
scaling up, dealing with multiple clusters, with related upgrades and management
On ES 6.0, the disk usage has been improved on sparse data segments.
Eg:
Segments like these
|
Joe |
Paris |
7 |
|
Lynn |
Madrid |
8 |
|
Robert |
Berlin |
1 |
|
Lynn |
NULL |
NULL |
Renault |
Madrid |
34500 |
|
Robert |
31 |
Accountant |
NULL |
Berlin |
23400 |
|
Joe |
25 |
CEO |
NULL |
Paris |
67000 |
|
Frank |
39 |
NULL |
Mercedes |
NULL |
NULL |
wouldn’t result in the following merged segment anymore:
|
Joe |
25 |
CEO |
NULL |
67000 |
Paris |
7 |
|
Lynn |
NULL |
NULL |
Renault |
34500 |
Madrid |
8 |
|
Robert |
31 |
Accountant |
NULL |
23400 |
Berlin |
1 |
|
Frank |
39 |
NULL |
Mercedes |
NULL |
NULL |
NULL |
Resulting in a disk space gain up to 45% on some cases.
Other aspects improved with this major release, are the resiliency and recovery system.
In the 5.x versions, a replica stopped by the temporary absence of the primary node, would result in a merging of the lost segments during the eventual recovery process.
Instead a transation-log recovery system has been implemented with the task of replacing only the lost segments.
On the upgrade process, is now possible to migrate from 5.x to 6.x seamlessly without the need for a full restart (provided that encryption via TLS has been implemented)
Some other improvements are the full implementation of a HIGH LEVEL Java REST client, built on the LOW LEVEL Java REST client present in ES 5.x
Regarding the roadmap for versions 6.1/6.2 , the main features will be:
– The possibility of splitting shards
– adaptive replica selection (balancing replica on lighter nodes in the cliuster)
– paging aggregation
– support for Java 9 (from ES 6.2)
– Plugin extensibility via SPI (ES 6.2)
Ingesting data into Elasticsearch
Ingestion presents many problems and challenges; notably volumes of data and disparity.
Here’s a typical scenario:
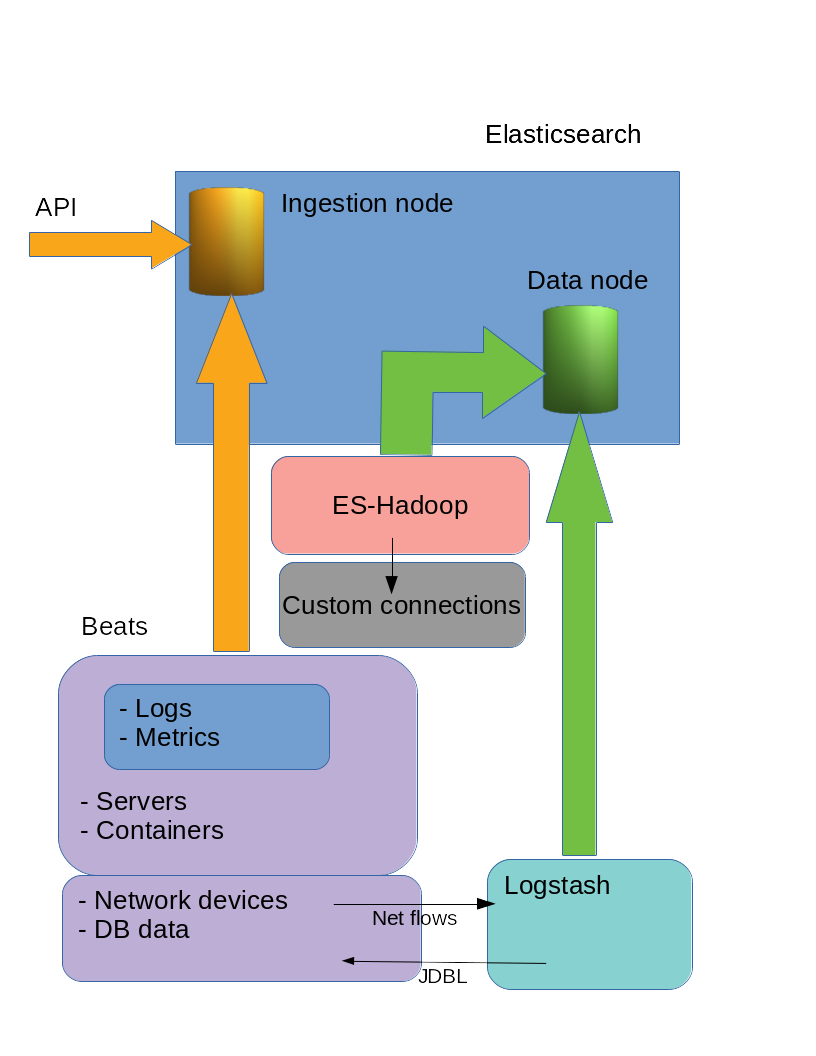
Many improvements have been done on Logstash:
– multi pipeline (pipelines segmented)
– Java event-rewrite
– events not anymore on the RAM but in disk
– dead letters queues
– cooperative ingestion
– easy migration between ingest technologies
Renault Datalake
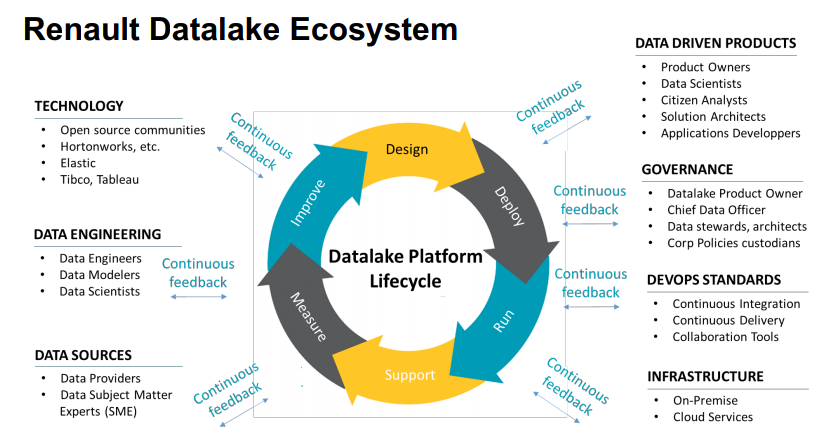
A business-oriented experience of Elastic technologies has been presented at the conference.
Starting form 2015 with an exploration phase of almost an year, Renault launched an internal project called Datalake.
This project aim is to trasnform the business to a “data-driven” organization.
A timeline of the phases (exploration,enabling,optimisation,accellerationa dn industrialisation) has been presented, along with some technical statistics and data.
5 data nodes, 90 indices each of roughly 6TB for an average of 300TB of data volume are the numbers behind 35 projects and 66 data sources at Renault.
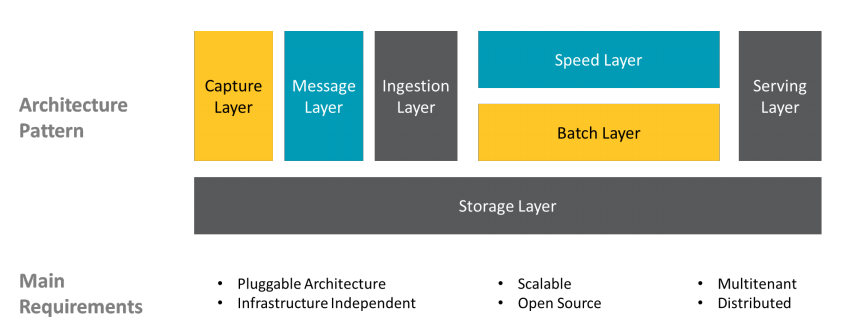
A design pattern consisted of layers has been chosen for this project with a storage layer beneath all the others (capture layer, message layer, ingestion layer, speed and batch layer, serving layer) and the usecases for which this infrastructure has been used are incidentology, marketing intelligence, business KPI (key performances indicator) and operational.
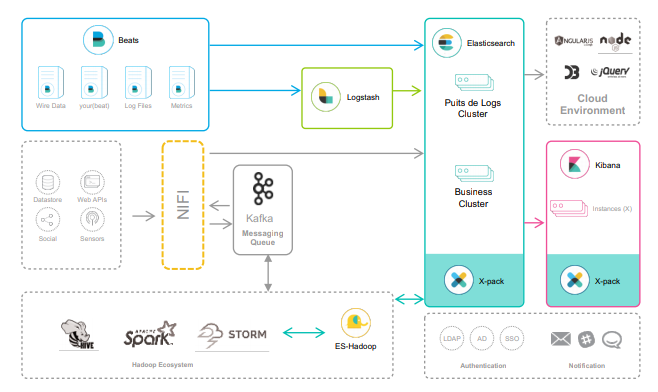
Some notes on the deployment have been presented as well, with the main challenges represented by a custom Oauth realm to support AWS apps, a good integration between IT and internal services and a Prometheus deployment to complete Marvel metrics; however Elastic acted as consultant for this infrastructure easing the workload.
Machine Learning
Baha Azarmi, solution architect at Elastic, explains the new machine learning features of the Xpack.
After a brief description on what does it mean to apply machine learning to data and which are the limitations of dashboards; for example in case of pattern-changing data, which threshold might be chosen and who will update it over time?
A real-world case is being analyzed: the Amazon AWS service brief downtime occurred on February the 27th 2017 at 9:37 CEST and subsequently a demo on machine learning is being given.
The setup is really simple and it involves just some clicks on a specific dashboard, a stream of data to be analyzed, some settings and a “learning phase” will immediately begin.
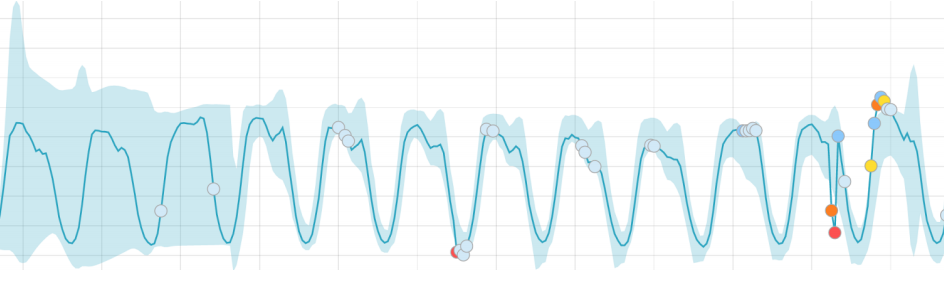
During that, the system will create an expected pattern of data variation, hence every little variation form the constructed model will be reported as suspicious.
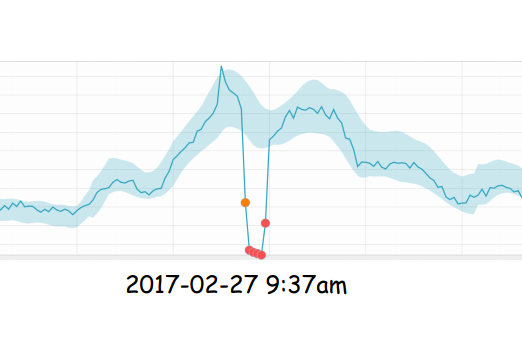
This allows anomalies to be easily detected and some security usecases are brought as examples
Elastic Suite integration in Amadeus
Another Elastic Suite business case is brought to the conference and this time is Amadeus, with Aymeric Gerardin and Luca Belluccini, an enterprise that has people dislocation at its core business, that will give a glimpse on how Elastic has been integrated in their experience.
After a presentation on the enterprise activities, customers and solutions, some impressive data statistics have been showed to the audience (1.3 Petabytes of produced data every day), thus the arising need to index and organise them.
Some usecases for this infrastructure are :
-
Skeptik (for user behaviour analysis)
-
Arcane (for human/robotic activity analysis)
-
SIEMonster as SOC
Elastic gave support for the whole endeviour with some on-site workshops, furthermore the best practises from Elastic Documentation have been followed and Xpack has been used.
After showing some information on the architecture, sizing and infrastructure, configuration and deployment, monitor and alerting, security and backups, the audience is left with a list of custom applications able to “speak” with Elastic.
Some remarks on the future of this project, such as an OpenShift integration, improvements on client libraries and improvements on change tracking have been revealed and the final takeaway is that Elastic have great impacts on people, processes and the push for growing.
Kibana 6.0
Melvyn Peignon takes the stage and explains the new features of Kibana 6.0 with a live demo session.
Much have been done in terms of functionalities, however aestethically the only notable is the new color, a deep blue that’s supposed to enhance the contrast on the screen.
A login screen has been added, along with different keyboard support and a new whole tab called “getting started” is now present.
Getting started gives a glimpse on what are the possible usecases and helps the user to set up one of them.
In the “discovery” tab, the filter wizard has been redesigned, a new query language (Kuery) has been added, but it must be enabled in the advanced settings and a “view surrounding documents” is now present.
On the “reporting” side, is finally possible to export CSVs.
The visualizations have been improved as well, with Vega, Timelion, the visual builder and the controllers playing a big role as a result.
On the dashboards, the only news is the “Elastic Maps”, however Xpack brings a new user management, the watcher as alerting service (capable of sending emails, generate logs or push to Slack rooms).
On the future of the application, some new features will be added, such as a user-accessibility management (called Spaces) that should show relevant logs based on the “role” of the user (developer/Sales/Security). A SAML support is on route and an API for saved objects will be added as well. Finally “Canvas” as part of Xpack will give the possibility of generate executive reporting and export them.
ElastiCloud Enterprise
The last contribution is from Sylvain Wallez, sogtware engineer at the cloud team in Elastic. His task is to explain what is ElastiCloud Enterprise and why an organisation might use it.
Usually a typical Elastic stack adoption follows this timeline in an enterprise environment:
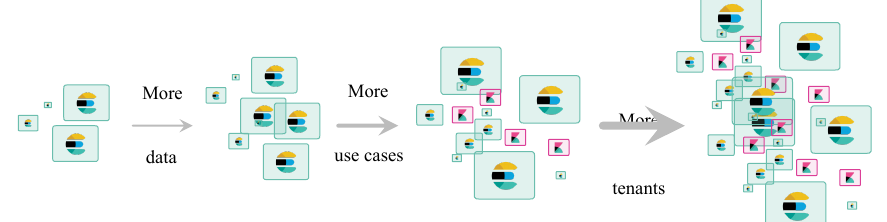
hence the necessity of keeping “things clean” but scalable and functional.
A single cluster is not a feasible option (easy to maintain but not flexible enough) and neither a multi-cluster approach is easy to manage (very flexible but difficult to maintain).
Different data life cycles, different access profiles, different SLAs, different backup policies, data isolation not complete and true fair-use impossible are some of the challenges that a multiple clusters environment presents.
Due to their multi-cluster experience at Elastic and a partnership with Amazon AWS, is now possible with ElastiCloud Enterprise a very easy management of multiple and very scalable clusters.
ElastiCloud in fact acts as a central management for upgrades,scaling,failure recovery and backups. Is deployable anywhere, from bare-metal to public cloud and gives the possibility of central logging for many clusters.
The core architecture:

is composed by a “Zookeeper” that holds the configurations of every single cluster, that allows the constructor to build images of the desired configuration, passing then it to the allocators that will coordinate the deployments of the clusters via the Allocators.
A live Demo is then presented and a brief access to the Management interface shows that is possible to choose the cluster version (6.0.1/5.6.5/2.4.6) , allocate the resources and choose the plugins, along with the cluster role for every “zone”.
References:
https://www.elastic.co/assets/blt00ffd5f2938d3165/elasticon-tour-2017-paris-ingest-deep-dive.pdf
https://www.elastic.co/assets/blt7bd2b53c11f4b73d/elasticon-tour-2017-paris-renault.pdf
https://www.elastic.co/assets/blte5d38dbdca853659/elasticon-tour-2017-paris-amadeus.pdf
https://www.elastic.co/assets/blta6492bd2510ad2a0/elasticon-tour-paris-kibana.pdf
