
Or What Splunk Cloud teaches us about managing an on-premises infrastructure?
Disclaimer
These are key points on the difference and benefits/drawbacks from its author’s perspective and this do not reflect the opinion of Hacknowledge nor the Analytics team of Hacknowledge.
This article highlights points that are important considering its author and does not target to be exhaustive. If you are seeking a complete Splunk Cloud description you can have a look at the official documentation here: https://docs.splunk.com/Documentation/SplunkCloud/latest/Service/SplunkCloudservice#Splunk_Cloud_Platform_Service_Details
Hacknowledge remains a vendor-neutral company even though providing its service over multiple technology stacks i.e., a SIEM agnostic MSSP provider.
TL;DR
Splunk Cloud is a cloud-based version of the popular log analysis and data management tool, Splunk Enterprise. It is designed for organizations that want to access the benefits of Splunk without the overhead of managing their own infrastructure. Every architecture is possible with hybrid Splunk Enterprise and Splunk Cloud infrastructures using Federated Search and/or On-premises forwarder to parse and transform the data before sending it to the cloud.
Managing a Splunk Cloud infrastructure teaches us many things that can be applied to Splunk Enterprise (on-premises) infrastructures such as scheduled maintenance, App vetting, Continuous Integration, log volume optimization, log management, or even in designing robust, not-too-complex systems that work.
Introduction
As an experienced Splunk Enterprise Administrator and Splunk Core Certified Consultant, I had the opportunity to follow the Transitioning to Splunk Cloud training, and I would like to share my feedback on Splunk Cloud.
In this blog post, we will go through the differences, advantages, and drawbacks of Splunk Cloud compared to Splunk Enterprise and its integration with an existing Splunk Enterprise deployment.
I must admit my experience on Splunk Cloud was limited because we do not have as many Splunk Cloud customers as we do for Splunk Enterprise. This is mainly due to three factors:
- Sensitivity of the data: Our customer base is concerned about where and under which conditions/regulations their data is stored as it may be sensitive. Data is encrypted at rest and you can bring your own encryption key (already available for Splunk Cloud Classic and soon available for Splunk Cloud Victoria Experience)
- Lack of experience with the solution from the partners: It is common among the Splunk partners that they have more experience with Splunk Enterprise, thus they are less prone to advise a customer to go for Splunk Cloud.
- Long history of lack of customization on the platform: It is true that Splunk Cloud Classic (explanation on the two flavors of Splunk Cloud later in the article) was not as customizable/manageable as an on-premises Splunk Enterprise deployment.
Splunk Cloud Classic vs Splunk Cloud Victoria Experience
Wait there are two versions of Splunk Cloud even if everybody was already confused with one?

No worries the Classic experience is the legacy one and gets replaced by Victoria soonTM (nothing to do with the Queen by the way😊). It fulfills many lacking features that prevented people from even considering Splunk Cloud[1].
- Self-service app installation is possible and seamless on Splunk Cloud Victoria[2]. Before that, admins would have to create a support ticket to install an App. This includes custom-developed Apps. After an automated vetting directly on the Splunk Cloud Search Head[3]. For customers with specific needs, it was painful before especially doing short-term consulting missions as it would slow down the development and deployment process.
- Inputs Data Manager (IDM): You can think of it as your Splunk Cloud Heavy Forwarder that would manage all modular and scripted inputs. Previously, it was a dedicated instance, such inputs reside now directly on the Search Heads of your Splunk Cloud Deployment. From the standpoint of an App developer, it is a huge step forward as it means that if you have a Cloud Search Head Cluster you get High Availability features for your modular input which is still a sweet dream on Splunk Enterprise (on-premises)[4][5]
- This setup also encourages Cloud-to-Cloud data collection as it makes no sense to collect it on-premises to send it back to the Cloud.
- Hybrid Search: This feature lets you connect on-premises and cloud Splunk instances. It is replaced by Splunk Federated Search instead which allows more flexibility in connecting cloud and on-premises environments as it is Splunk’s goal. The editor is not pushing (anymore 😊) Splunk Cloud at all costs.
- HTTP Event Collector: The agentless way to send events to Splunk can be configured directly via the Cloud Search Head (Web) and the Admin Configuration Service (ACS) endpoints. This is the API to administer your Splunk Cloud infrastructure (another good point!).
Splunk Cloud vs Splunk Enterprise
The key differences between Splunk are presented in the documentation[6]. This article will highlight the most important ones from the standpoint of an on-premises Architect and Consultant.
We will not go over the usual Cloud vs On-Premises battle and assume everyone knows it saves infrastructure costs and scales more and so on and so forth 😀
Apps
Apps deployed to Splunk Cloud need to pass various tests to ensure the security and performance of the platform, this is called vetting. Splunkbase contains numerous already vetted Apps (Splunk Cloud compliant) that can be installed. Premium Apps such as Enterprise Security and ITSI still need a support ticket to be installed.
One can see this as a drawback for private (custom-developed) Apps as it needs to follow the same path as any other published App but it forces developers to sanitize their processes using continuous integration pipelines to make vetting automatic, versioning, and testing which is for the best on a production environment. At Hacknowledge we already follow this process for internal and customer-delivered Apps to test and deploy.
Command-line (CLI) access
This was my biggest fear as an admin that loves digging into configuration files and using the command line in general. Splunk Cloud being a managed Splunk deployment, the machine hosting the platform is, by definition, not accessible by the customer. While looking like a drawback, at Hacknowledge we like to see it as a process-oriented managed infrastructure 😉:
- A Splunk Dev instance can be deployed on-premises to assess configurations before pushing it to prod. By experience, customers often lack such instances even if they are fully on-premises.
- Packaging (whenever possible) every configuration in Apps. It is best practice not to do every configuration in the Web UI and reassemble the configurations as Apps.
- Forces to automate the process of configurations and App deployment.
The Admin Configuration Service (ACS) comes to the rescue for this last point! For this, I will shamelessly quote the documentation available here[7]:
The Admin Config Service (ACS) is a cloud-native API that provides programmatic self-service administration capabilities for Splunk Cloud Platform. Splunk Cloud Platform administrators can use the ACS API to perform common administrative tasks without assistance from Splunk Support.
The ACS API lets you:
- Configure IP allow lists
- Configure outbound ports
- Manage authentication tokens
- Manage HTTP Event Collector (HEC) tokens
- Manage indexes
- Manage limits.conf configurations
- Manage private apps and add-ons
- Manage Splunkbase apps
- Enable private connectivity
- View maintenance windows
- Manage restarts
REST API
Similarly to Splunk Enterprise, it is available on Splunk Cloud, you just need to enable it via a Support Ticket[8].
Data Location
Frankfurt AWS datacentre might be considered as if data resides in CH, in any case, it resides in the EU and is under GDPR regulation. This needs to be verified and assessed by your DPO internally.
Data Lifecycle
Like Splunk Enterprise (on-premises) Splunk Cloud uses buckets to store data in indexes. The minor difference is there is no notion of cold buckets since the storage layer is abstracted by the underlying S3 buckets (like Splunk Smart Store for on-premises users).
When data arrives in the indexer via an input, the following lifecycle happens:
- Hot: as in Splunk Enterprise data is first put into a hot bucket that is readable (searchable) and writable for incoming new data, hot buckets live in cache
- Warm: once rolled, a bucket is set to warm and copied to S3 storage, it is pulled back to the cache when searched for performance matters
- Frozen: when the bucket is rolling into the frozen state there are 3 options to choose from when defining the index
- Purge: the buckets (data) get deleted
- Archive
- Splunk Managed Archive (DDAS)
- Customer Managed Archive (DDSS)
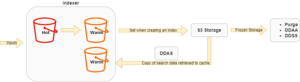
Bucket rolling from one state to another is analogous to Splunk Enterprise except for the fact that it might take the cache size into account for hot buckets.
Storage Options
Splunk Cloud proposes multiple storage options related to data lifecycle. For further details, you can go to the Splunk Cloud Service Description[9].
Dynamic Data Active Searchable (DDAS)
Dynamic Data Active Searchable (DDAS) is a storage service in Splunk Cloud Platform that should be sized according to the volume of uncompressed data to be indexed daily. DDAS can be purchased based on data retention requirements, and overages are true-up quarterly. Ingest-based subscriptions include DDAS to store up to 90 days of uncompressed data. The service elastically expands DDAS if needed, but consistently over-ingesting can impact search performance.
Dynamic Data Active Archive (DDAA)
Dynamic Data Active Archive (DDAA) is a lower-cost option for long-term data storage. As data ages, it is moved to DDAA before deletion based on the index retention setting. DDAA subscriptions include an additional 10% of DDAS for restores, but this additional storage should be reserved for restores, as exceeding the DDAS entitlement may incur a true-up cost. Restored DDAA data is typically searchable within 24 hours but can take longer for large amounts of data.
Dynamic Data Self-Storage (DDSS)
Dynamic Data Self-Storage (DDSS) allows users to export aged data from Splunk Cloud Platform to an Amazon S3 or Google Cloud Storage account in the same region. Users are responsible for payments for their use of Amazon S3 or Google Cloud Storage, and aged data is exported unencrypted.
How do I restore my frozen data?
Since Splunk Cloud uses S3 buckets to store data (Splunk SmartStore) for active and frozen data. On Splunk Enterprise (on-premises) deployment, it can be a pain to manage frozen data and make it cycle (stay tuned though as something might come from us😉) or restore it. With DDAA (see above), the data goes there when frozen and can be unfrozen (thawed) on-demand via the Splunk Cloud Search Head Web Interface.

Splunk Federated Search
Splunk federated search is a feature that allows users to search across multiple Splunk instances, including both Splunk Cloud and Splunk Enterprise, using a single search query. This enables users to easily access and analyze data from multiple sources, regardless of where that data resides.
In a Splunk Cloud and Splunk Enterprise hybrid infrastructure, federated search can be particularly useful. This type of infrastructure typically involves running a Splunk Enterprise instance on-premises or in a private cloud, while also using Splunk Cloud for certain workloads. By using federated search, users can easily search and analyze data across both environments without having to switch between different interfaces or log into separate instances.
Federated search also helps to ensure that users have access to all relevant data, regardless of where it is stored. For example, if a user is searching for a particular event that occurred across multiple systems, federated search can search across all of those systems simultaneously, rather than forcing the user to search each system separately. This can save time and improve the accuracy of search results.
Furthermore, federated search can help to improve data security and compliance. In a hybrid infrastructure, there may be certain data sources that cannot be stored in the cloud due to regulatory or compliance requirements. By using federated search, users can access this data from an on-premises instance of Splunk Enterprise, without having to transfer the data to Splunk Cloud.
Conclusion
Having experience with Splunk Enterprise, deployed, and managed multiple distributed infrastructures I must confess I was reluctant in proposing Splunk Cloud to our customers. With the new features present in the Splunk Cloud Victoria Experience, I am now confident in advising customers to go for it.
Feel free to reach out if you have any questions on Splunk Cloud (or Enterprise) and want to implement it at your company.
Hacknowledge Analytics
Are you concerned about the security of your business? Look no further than the Analytics team at Hacknowledge. Our team provides comprehensive guidance from log policy and management to threat detection and response.
All our team members are part of Hacknowledge’s SOC team, meaning they have firsthand experience handling alerts and writing detections. Our focus on excellence and customer-oriented service is reflected in all our senior engineers being Splunk Core Certified Consultants.
While we have a strong focus on Splunk technology, we remain vendor-neutral and provide unbiased advice to our customers, regardless of their existing technology. Trust us to provide the expertise and support you need to keep your business secure.
Hackowledge
Hacknowledge is a leading cybersecurity company part of the Swiss Post based in Morges, Switzerland, which specializes in providing comprehensive and tailored cybersecurity solutions to businesses of all sizes. Our team of highly skilled and certified cybersecurity professionals dedicated to ensuring that your business is safe against the ever-evolving threat landscape.
At Hacknowledge, we take an initiative-taking approach to cybersecurity by providing continuous monitoring, threat detection, and incident response services. We also offer vulnerability assessments, penetration testing, and security audits to identify potential weaknesses in your systems and provide recommendations for improvement.
Our solutions are designed to meet the specific needs of each client, and we work closely with our customers to ensure that they are always up to date with the latest cybersecurity best practices. We pride ourselves on providing excellent customer service and support, and we are committed to helping our clients achieve their cybersecurity goals.
In short, Hacknowledge is your trusted partner in cybersecurity, providing expert solutions and support to protect your business from cyber threats.
[1] Determine your Splunk Cloud Platform Experience – Splunk Documentation
[2] Install apps on your Splunk Cloud Platform deployment – Splunk Documentation
[3] Manage private apps on your Splunk Cloud Platform deployment – Splunk Documentation
[4] High-Availability for Data Collection Node (HWF) Modular | Ideas (splunk.com)
[5] Enable load balancing across multiple instances | Ideas (splunk.com)
[6] Splunk Cloud Platform Service Details – Splunk Documentation
[7] About the Admin Config Service (ACS) API – Splunk Documentation
[8] https://docs.splunk.com/Documentation/SplunkCloud/latest/RESTTUT/RESTandCloud
[9] https://docs.splunk.com/Documentation/SplunkCloud/latest/Service/SplunkCloudservice#Storage
